Ieri vi abbiamo parlato di Leadtools OCR, un’applicazione gratuita disponibile sul Mac App Store in grado di riconoscere ed estrarre il testo, ad esempio, da un’immagine scansionata e convertita in PDF. Nonostante l’applicazione si presenti bene, abbiamo visto come i risultati non siano sufficienti per un utilizzo quotidiano. Analizziamo ora un’alternativa, sempre gratuita, che a primo impatto sembra essere di qualità superiore: PDF OCR X Community Edition.
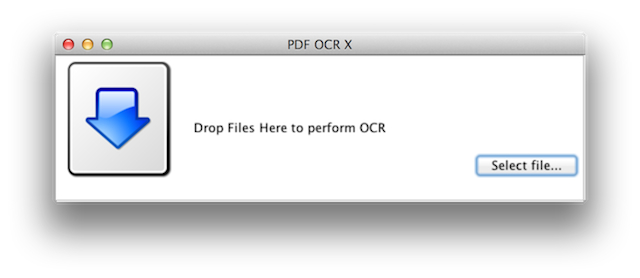
La prima cosa che notiamo è sicuramente l’eccessiva semplificazione dell’interfaccia: abbiamo infatti una piccola finestra in cui possiamo trascinare il file PDF oppure selezionarlo manualmente, cliccando sull’unico pulsante disponibile.
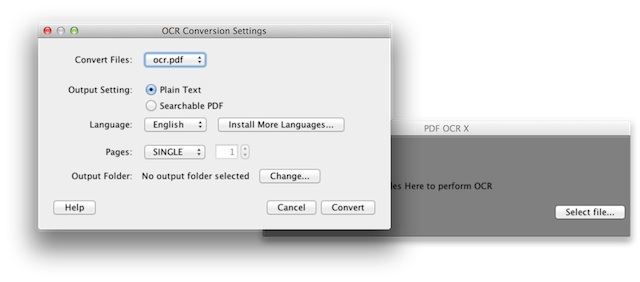
Trascinando un documento all’interno dell’applicazione possiamo accedere a delle opzioni leggermente più avanzate circa la lingua del file, il formato e la cartella di output. Inizialmente abbiamo a disposizione solamente la lingua inglese, ma è possibile installarne altre gratuitamente (il peso delle lingue varia dai 2 ai 15MB a seconda della complessità dei caratteri dell’alfabeto). Per l’Italiano possiamo scegliere tra “Italian” e “Italian (Old)”. Vi consigliamo di utilizzare la prima, in quanto più completa e ottimizzata. Selezioniamo quindi il tipo di file in output (il formato Searchable PDF esclude la possibilità di modifica successiva), la lingua, il numero di pagine e la cartella di output, e clicchiamo su Convert.
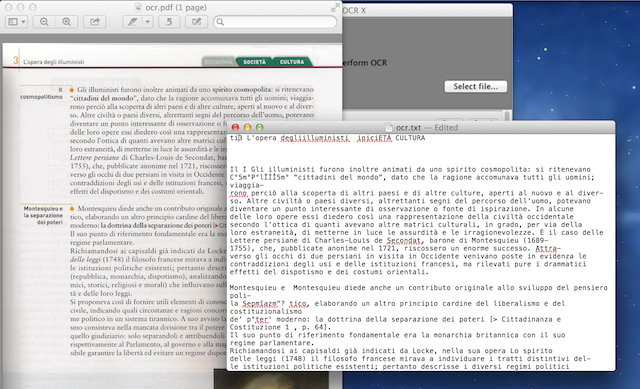
Il file di prova utilizzato è un PDF ottenuto tramite una scansione a 200 dpi, e il testo appare sufficientemente definito. Al termine della conversione, l’applicazione apre automaticamente il file appena creato, che avrà lo stesso nome del file originale ma con estensione .txt o .searchable.pdf. Per quanto riguarda l’estrazione del testo il risultato è buono, ma anche in questo caso è necessario intervenire e correggere i numerosi errori commessi dal software (non tanto nel riconoscimento del testo vero e proprio quanto nell’impaginazione dello stesso). Ad esempio nel caso avessimo delle didascalie affiancate a un testo principale, esse vengono considerate parte della stessa riga e mischiate con il resto del testo in un unico paragrafo, stravolgendo completamente il senso delle frasi.
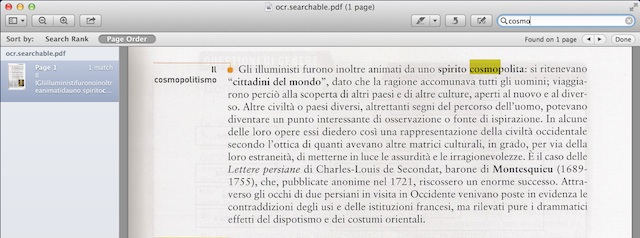
Per quanto riguarda invece la conversione a PDF testuale, il risultato è leggermente peggiore (utilizzando lo stesso file): provando a evidenziare una parte di testo, o a ricercare una parola all’interno di esso, ci accorgiamo che mancano quasi completamente gli spazi tra le parole e la ricerca non riconosce correttamente i termini da noi richiesti.

Conclusioni
PDF OCR X Community Edition mostra qualche indecisione nel riconoscimento del testo in italiano se si effettua la conversione a PDF testuale, mentre si comporta molto meglio con la semplice estrazione. La differenza principale con Leadtools sta, oltre che nella possibilità di creare file PDF con il testo selezionabile (non possibile con Leadtools), nel fatto che utilizzando un’immagine un po’ meno definita (ad esempio un PDF scansionato a 100dpi), PDF OCR X riconosce comunque abbastanza bene i caratteri e il margine di errore aumenta di poco: aspetto da non sottovalutare considerando che si tratta di un applicativo gratuito. Per fare un confronto pratico tra Leadtools OCR e PDF OCR X abbiamo provato ad estrarre la stessa immagine con entrambi i programmi, utilizzando prima un PDF a 200 dpi e poi a uno a 100 dpi. PDF OCR X è risultato nettamente superiore, riuscendo a convertire in modo molto più preciso e fedele la maggior parte delle parole in entrambi i casi. Se però PDF OCR X guadagna punti in funzionamento e disponibilità di più formati di output, li perde in ricchezza dell’interfaccia, che risulta decisamente povera. Segnaliamo inoltre la presenza della versione Enterprise a pagamento di PDF OCR X, che aggiunge alcune funzioni come la memorizzazione delle impostazioni di conversione, evitando così di doverle inserire manualmente ogni volta, e la possibilità di convertire più file insieme (nella versione gratuita se ne può convertire solo uno alla volta). Se avete bisogno quindi di un software gratuito per estrarre il testo dai PDF, e avete a disposizione PDF ben definiti, PDF OCR X è una valida scelta, soprattutto considerato che è gratuito.
 Oltre a richiedere rispetto ed educazione, vi ricordiamo che tutti i commenti con un link entrano in coda di moderazione e possono passare diverse ore prima che un admin li attivi. Anche i punti senza uno spazio dopo possono essere considerati link causando lo stesso problema.
Oltre a richiedere rispetto ed educazione, vi ricordiamo che tutti i commenti con un link entrano in coda di moderazione e possono passare diverse ore prima che un admin li attivi. Anche i punti senza uno spazio dopo possono essere considerati link causando lo stesso problema.