Un tempo per effettuare il riconoscimento ottico dei caratteri di un pagina stampata si ricorreva a software molto complessi e spesso costosi, oggi esiste un’app gratuita sul Mac App Store che si chiama Leadtools OCR. La mettiamo alla prova consapevoli che non ci possiamo aspettare gli stessi risultati di applicazioni di riferimento per la categoria, ma essendo gratuita siamo pronti ad accettare qualche compromesso in termini di funzionalità. Appena aperta l’interfaccia si presenta molto snella e di facile comprensione, con una miniatura del documento a sinistra, lo stesso aperto più grande al centro ed una toolbar con le funzioni. Proviamo subito con il documento di prova già precaricato (in inglese) e ci da buoni risultati di riconoscimento, ma vogliamo provare con una pagina scandita da noi e in italiano.
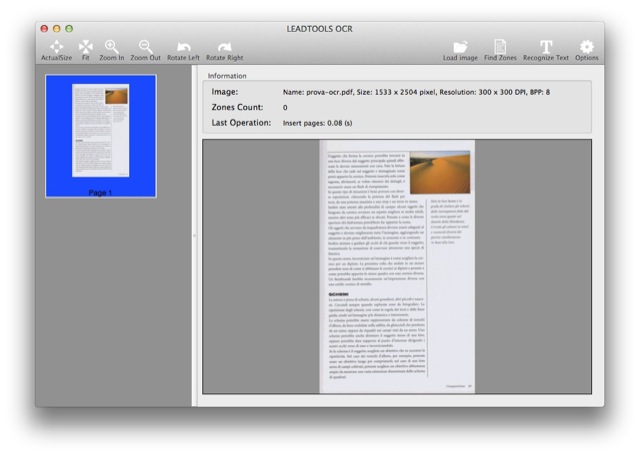
Scegliamo File / Open ed apriamo un documento in PDF appena ottenuto tramite scanner e l’app Anteprima, catturato a 150 dpi dalla pagina di un libro. Il testo appare un po’ morbido, non ha contorni particolarmente incisi, ma proviamo lo stesso a completare l’operazione. Per prima cosa utilizziamo il pulsante in alto a destra “Find Zones”, il quale identifica automaticamente e borda di rosso le aree del documento che contengono del testo:
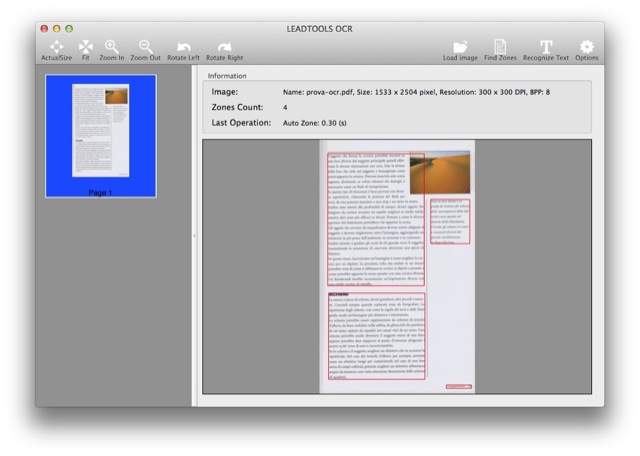
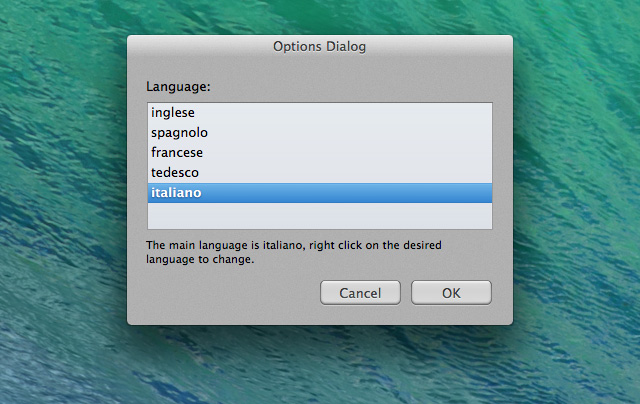
Prima di procedere clicchiamo su “Options” e vediamo che la lingua italiana è attiva, ma non è la predefinita. Purtroppo questa finestra non funziona bene perché è difficile deselezionare l’inglese, ma, soprattutto, non memorizza le preferenze, per cui dovremo modificarla manualmente ogni volta. In tutti i casi abbiamo riscontrato che il riconoscimento in lingua italiana avviene comunque anche se la lingua predefinita è l’inglese, per cui si può anche lasciare così com’è.
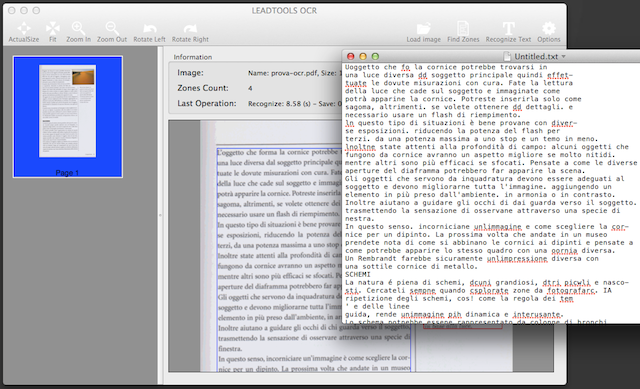
Una volta identificate le aree di testo clicchiamo sull’icona “Recognize Text” e ci verrà richiesto il nome di un file di testo in cui salvare il risultato. Con il nostro PDF di prova abbiamo riscontrato numerosi errori di riconoscimento, uno o due per ogni riga. Ovviamente si tratta di un risultato scadente che richiede una profonda correzione manuale, anche se può essere comodo trovarsi con il grosso del testo già pronto.

Conclusioni
Con il documento di prova in inglese Leadtools OCR si è dimostrata all’altezza delle aspettative, mentre messa a confronto con un documento appena acquisito dallo scanner e in lingua italiana ha mostrato parecchi limiti. A quanto pare il problema principale è la qualità dell’immagine che gli si fornisce, perché se questa è morbida e poco contrastata si va incontro ad una grande quantità di errori. Migliorando l’immagine sorgente ho attenuto una parziale riduzione di errori, ma il risultato richiede sempre un notevole intervento di correzione. Tutto sommato può essere sufficiente per un uso sporadico vista la gratuità, ma non supera la sufficienza nella nostra valutazione.
 Oltre a richiedere rispetto ed educazione, vi ricordiamo che tutti i commenti con un link entrano in coda di moderazione e possono passare diverse ore prima che un admin li attivi. Anche i punti senza uno spazio dopo possono essere considerati link causando lo stesso problema.
Oltre a richiedere rispetto ed educazione, vi ricordiamo che tutti i commenti con un link entrano in coda di moderazione e possono passare diverse ore prima che un admin li attivi. Anche i punti senza uno spazio dopo possono essere considerati link causando lo stesso problema.